

Si alguna vez te has preguntado por qué unas páginas aparecen en Google y otras no, este artículo es para ti. Vamos a entrar de lleno en cómo funciona Google: desde el rastreo hasta la indexación y el ranking final en los resultados de búsqueda. Te lo voy a explicar con calma, como si estuviéramos en una sesión estratégica de EximiaStudio revisando juntos tu web.
La mayoría de personas piensa que basta con publicar una página para que aparezca en Google. Error. Antes de que un usuario pueda ver tu web, Google tiene que descubrirla, analizarla y decidir en qué posición mostrarla. Y aquí es donde entra en juego todo el proceso de crawling (rastreo), indexación y ranking.
En este artículo vamos a cubrir todo lo que necesitas saber: qué significa cada fase, cómo afecta a tu negocio digital, qué herramientas puedes usar, los errores más comunes y por qué contar con un profesional puede marcar la diferencia. Lo vamos a ver de forma sencilla para que cualquiera lo entienda, pero también con la profundidad suficiente para que, si eres marketer o SEO avanzado, saques valor y nuevas ideas.
Qué es el rastreo en Google y por qué es clave para tu web
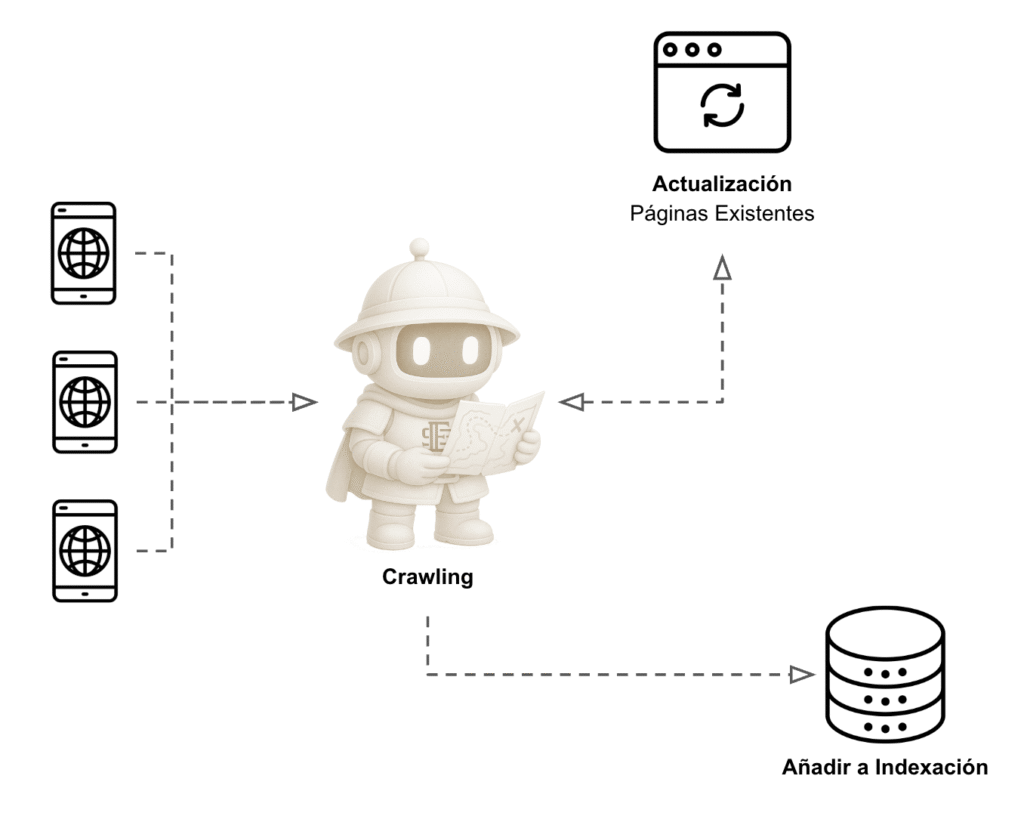
Antes de hablar de posicionar tu web, necesitas entender cómo Google la descubre. El rastreo (o crawling) es el primer paso, y sin él no hay nada más.
En palabras simples, Google envía unos robots llamados Googlebot que recorren Internet saltando de enlace en enlace, revisando cada página que encuentran. Piensa en ellos como una araña que sigue cada hilo de una telaraña digital. Si tu web no tiene enlaces internos bien estructurados o no aparece enlazada desde otros sitios, será mucho más difícil que Google la rastree.
¿Qué técnicas utilizan los robots para rastrear y recopilar información de una web?
Los robots de los buscadores no navegan al azar, siguen un conjunto de técnicas que les permiten encontrar, entender y organizar el contenido de tu sitio. Aquí te explico las más importantes con ejemplos sencillos:
Seguimiento de Enlaces
Piensa en un robot como una persona navegando por internet. Llega a tu página de inicio, encuentra un enlace hacia tu blog y lo sigue. Una vez en el blog, descubre enlaces a artículos individuales y también los visita. Así, poco a poco, el robot va recorriendo tu web y descubriendo nuevo contenido.
Los enlaces internos bien estructurados ayudan a que el bot llegue a todas las secciones importantes de tu sitio.
Normalización de URLs
Muchas veces la misma página puede mostrarse bajo diferentes URLs. Para un buscador, estas variaciones pueden parecer páginas distintas, aunque en realidad no lo sean:
https://ejemplo.com/paginahttps://ejemplo.com/pagina/https://ejemplo.com/PAGINA
Los robots aplican normalización de URL para entender que todas apuntan al mismo recurso. Esto evita que tu contenido se interprete como duplicado y optimiza el rastreo.
Uso de Robots.txt
Antes de empezar a explorar, los bots suelen mirar si existe un archivo especial llamado robots.txt en la raíz del dominio. Este archivo funciona como un libro de instrucciones: indica qué partes de la web se pueden rastrear y cuáles no.
Por ejemplo, puedes permitir que rastreen tu blog pero bloquear el acceso al área privada de usuarios. Los robots “bien educados” respetan estas reglas, aunque no todos lo hacen.
Entender el contenido de la página
Cuando el robot carga una página, no la ve como tú en el navegador, sino como código HTML. A partir de ahí, analiza:
- El título de la página.
- Encabezados (
<h1>,<h2>, etc.). - Párrafos y enlaces.
- Imágenes y sus atributos.
- Metadatos como la descripción.
Por ejemplo, si tienes un <h1>10 consejos para mejorar tu SEO</h1>, el bot lo identifica como el tema principal de la página. Este análisis ayuda a los buscadores a clasificar tu contenido correctamente.
Descubrimiento de nuevo contenido
Una vez dentro, el robot no se queda en una sola URL. Va siguiendo los enlaces que encuentra y va añadiendo nuevas páginas a su lista de rastreo. Este proceso se repite hasta que ha cubierto todo lo que puede.
Si una página no tiene enlaces internos ni externos que la apunten, se convierte en una “página huérfana”. En la práctica, los buscadores suelen ignorarlas porque no tienen forma de encontrarlas fácilmente.
Sitemaps XML (mapas de sitio)
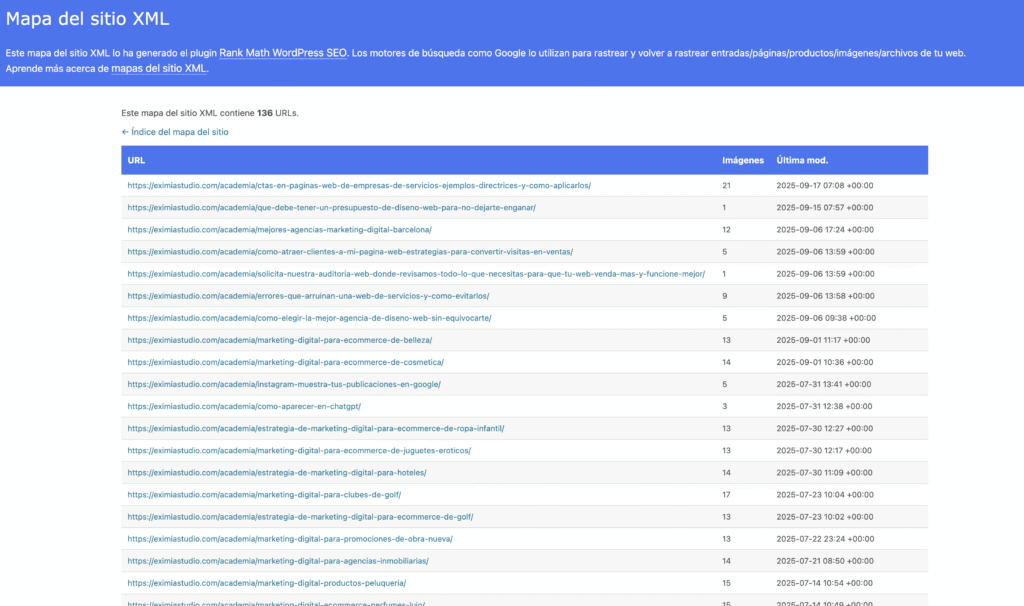
Para asegurarte de que todas tus páginas, incluso las huérfanas, puedan ser descubiertas, los buscadores permiten enviar sitemaps XML. Este archivo actúa como un índice que indica qué páginas existen, cuándo se actualizaron y su importancia relativa.
Es como un mapa de tu sitio que le dice a Google qué páginas existen y cómo están organizadas. En EximiaStudio siempre recomendamos subirlo a Search Console para asegurarnos de que las páginas importantes son rastreadas de inmediato.
Un sitemap bien estructurado mejora la eficiencia del rastreo y garantiza que no se queden páginas importantes sin descubrir.
Los robots siguen enlaces, normalizan URLs, respetan (en teoría) las reglas de robots.txt, leen el HTML, descubren nuevas páginas a través de enlaces y se apoyan en los sitemaps. Cuanto más claro y ordenado esté tu sitio, más fácil será para ellos rastrearlo y para ti posicionarlo.
Principales arañas y bots de Crawling
Además de Googlebot, que es el más conocido, existen decenas de arañas (también llamadas crawlers o spiders) que visitan tu web para indexarla, analizarla o mostrarla en diferentes plataformas. Algunas pertenecen a buscadores, otras a redes sociales y otras a herramientas SEO. Conocerlas te ayuda a entender por qué ves determinadas visitas en tus logs de servidor y cómo gestionar su acceso desde el archivo robots.txt.
Aquí tienes una lista con los 20 bots de rastreo más comunes y relevantes:
- Googlebot (Google Search) → el bot principal que indexa páginas en Google.
- Google-InspectionTool (Google Search Console) → pruebas de indexación y rich snippets.
- AdsBot-Google (Google Ads) → revisa la calidad de las páginas de destino de anuncios.
- bingbot (Microsoft Bing) → bot de rastreo de Bing.
- Baiduspider (Baidu) → motor de búsqueda líder en China.
- YandexBot (Yandex) → buscador ruso.
- DuckDuckBot (DuckDuckGo) → rastreador de este buscador centrado en privacidad.
- Applebot (Apple) → usado en Siri, Spotlight y Safari Suggestions.
- PetalBot (Huawei) → rastreador de Petal Search.
- Sogou Spider (Sogou) → buscador chino.
- Yeti (NaverBot) (Naver) → buscador coreano.
- SeznamBot (Seznam.cz) → buscador checo.
- Exabot (Exalead) → motor de búsqueda francés.
- CCBot (Common Crawl) → proyecto abierto de rastreo masivo para investigación.
- AhrefsBot (Ahrefs) → herramienta SEO y su buscador Yep.
- SemrushBot (Semrush) → otra de las grandes herramientas SEO.
- MJ12bot (Majestic) → especializado en análisis de backlinks.
- DotBot (Moz) → bot de la suite de Moz para indexar y analizar.
- Meta Crawlers (Facebook, Instagram, Messenger) → generan las previsualizaciones de enlaces (
facebookexternalhit,Facebot). - Twitterbot (X/Twitter) → muestra las Twitter Cards al compartir links.
🔎 Tip práctico: aunque estos user-agents son los oficiales, ten en cuenta que algunos bots pueden falsificar su identidad. Si necesitas verificar si realmente un acceso es de Google, Bing u otro buscador legítimo, lo más fiable es comprobar la IP y el reverse DNS.
A nivel técnico, la frecuencia y profundidad del rastreo dependen de factores como:
- La autoridad y popularidad de tu dominio.
- La frecuencia con la que actualizas contenido.
- El rendimiento de tu servidor (si tu web carga lenta, Googlebot puede desistir).
- La calidad del enlazado interno.
Un ejemplo práctico: imagina que acabas de lanzar una sección de “Blog” en tu web. Si no enlazas esos artículos desde la home o desde un menú accesible, Google tardará mucho más en descubrirlos.
Qué significa indexación y cómo decide Google qué páginas guardar
Una vez que un robot ha rastreado tu página, la envía al proceso de indexación. Aquí Google no solo guarda la información, sino que la analiza a fondo para decidir si merece estar en el índice y cómo clasificarla. Estos son los aspectos más relevantes que revisa:
- Calidad y originalidad del contenido. Google evalúa si el texto aporta valor real, si es único frente a otras páginas de la web o de internet, y si está bien redactado y estructurado. El contenido duplicado, pobre o poco útil suele ser descartado o filtrado.
- Estructura HTML y semántica. El buscador interpreta el código de la página:
- Jerarquía de encabezados (
<h1>,<h2>,<h3>). - Etiquetas meta (
title,description). - Datos estructurados (schema) que ayuden a entender el contexto.
Una estructura clara facilita que Google comprenda el tema central y cómo se organiza la información.
- Jerarquía de encabezados (
- Recursos visuales (imágenes, vídeos, elementos multimedia). Google analiza las imágenes junto con sus atributos
alt, títulos y contexto en la página. También puede indexar vídeos y elementos embebidos si están correctamente implementados. - Enlazado interno y contexto global del sitio. Se revisa cómo encaja la página dentro de la arquitectura del sitio:
- Qué páginas internas apuntan a ella.
- Qué relevancia y autoridad transmite a otras secciones.
- Si está accesible desde menús, sitemaps y rutas lógicas.
Una página aislada (sin enlaces internos) tiene menos probabilidades de ser indexada.
- Detección de duplicidades y thin content. Google filtra páginas demasiado similares, con contenido escaso o generadas automáticamente. También revisa versiones canónicas para evitar indexar duplicados innecesarios.
- Rendimiento técnico y experiencia de usuario. Aunque el rastreo es la fase donde más influye la velocidad del servidor, en la indexación también importa que la página cargue rápido y se pueda renderizar correctamente, sobre todo si depende de JavaScript.
- Compatibilidad móvil y accesibilidad. El índice de Google es mobile-first, lo que significa que evalúa la versión móvil de la página como principal. Problemas de usabilidad móvil o bloqueos de recursos pueden afectar a la indexación.
- Señales de autoridad y contexto externo. Aunque los enlaces entrantes influyen más en la clasificación, durante la indexación Google también puede valorar si la página pertenece a un sitio con autoridad y confianza o si parece de baja calidad.
Aquí es donde muchas webs fallan. Puedes tener un sitio precioso, pero si Google lo considera duplicado, irrelevante o demasiado fino en contenido (thin content), puede decidir no indexarlo.
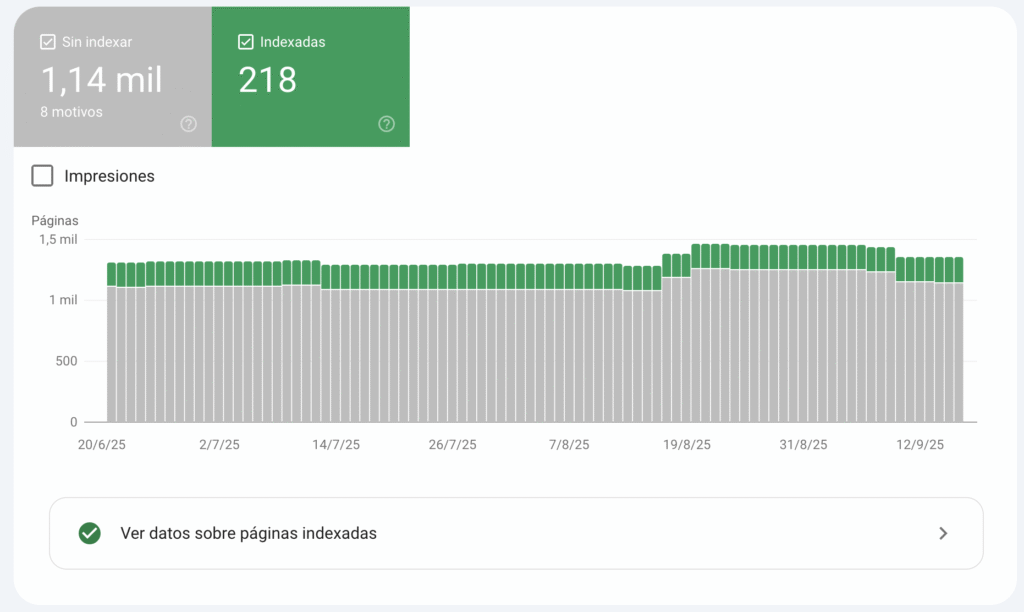
Un caso clásico: empresas que crean decenas de páginas con el mismo texto cambiando solo el nombre de la ciudad (“Abogados en Madrid”, “Abogados en Barcelona”…). Google suele descartar la mayoría porque no aportan valor único.
¿Cómo saber si una página está indexada en Google con Search Console?
Una cosa es que Google haya rastreado tu página, y otra muy distinta es que la haya indexado y aparezca en los resultados de búsqueda. Para comprobarlo de forma precisa, la herramienta más útil es Google Search Console.
Paso 1: Accede a la barra de inspección de URL. Dentro de Search Console, verás en la parte superior un campo donde puedes pegar la dirección exacta de la página que quieres revisar.
Paso 2: Introduce la URL. Pega la dirección completa (incluyendo https:// y cualquier subcarpeta) y pulsa Enter.
Paso 3: Revisa el estado de indexación. Google te mostrará uno de estos mensajes principales:
- ✅ La URL está en Google: significa que la página ya está indexada.
- ⚠️ La URL está en Google, pero con problemas: puede estar indexada con advertencias (ejemplo: contenido duplicado o problemas de cobertura).
- ❌ La URL no está en Google: indica que no ha sido indexada todavía.
Paso 4: Solicitar indexación (si no lo está)
Si tu página no está indexada, Search Console te da la opción de “Solicitar indexación”. Esto envía una petición directa a Google para que vuelva a rastrear esa URL y considere añadirla a su índice.
En EximiaStudio lo que hacemos es asegurarnos de que cada página clave tenga contenido único, trabajado y alineado con la intención de búsqueda del usuario. Solo así nos aseguramos de que la web no solo se rastree, sino que además entre en el índice de Google.
Ranking: cómo decide Google qué páginas aparecen primero
Ahora viene la parte más competitiva, el ranking. Una vez que tu página está indexada, Google debe decidir dónde mostrarla en los resultados de búsqueda.
Este ranking no es aleatorio. Google utiliza cientos de señales conocidas como ranking signals. Algunos de los más importantes son la relevancia semántica, la autoridad del dominio, la experiencia de usuario, la frescura del contenido y aspectos técnicos como los Core Web Vitals. Si quieres profundizar en los factores que influyen en el posicionamiento web con SEO, te recomiendo revisar nuestra guía detallada donde analizamos qué está marcando la diferencia este año.
- Relevancia semántica: si tu contenido responde a lo que el usuario busca.
- Autoridad del dominio: basada en enlaces externos de calidad (backlinks).
- Experiencia de usuario: velocidad de carga, usabilidad en móvil, interacciones.
- Frescura del contenido: Google prefiere artículos recientes en temas que cambian rápido.
- Factores modernos: Core Web Vitals, seguridad HTTPS, estructura de datos.
Imagina que alguien busca “mejores zapatillas para correr 2025”. Google no solo mirará qué páginas hablan de zapatillas, sino también cuáles aportan comparativas recientes, están bien enlazadas y ofrecen una buena experiencia al usuario.
Aquí es donde la estrategia SEO se convierte en arte y ciencia. No basta con optimizar títulos o meter keywords: necesitas un ecosistema completo que combine contenido de calidad, autoridad externa y una web técnicamente impecable. Así conseguiremos
Errores comunes que bloquean el proceso de Google
Antes de pasar a la parte práctica, es importante conocer los fallos más habituales que pueden impedir que Google rastree, indexe o posicione una web correctamente. Estos son algunos de los que más vemos cuando analizamos proyectos en EximiaStudio:
Errores que bloquean el rastreo
- Bloquear por accidente en robots.txt
UnDisallow: /o el bloqueo de carpetas críticas (ej./wp-content/,/css/,/js/) puede dejar tu web oculta o mal renderizada para Google. - No enviar un sitemap XML actualizado
Sin sitemap, Google depende solo de enlaces internos/externos. Esto complica el descubrimiento de páginas nuevas o profundas. - Exceso de parámetros en las URLs
Filtros, sesiones o URLs dinámicas infinitas generan duplicados que consumen el crawl budget. - Errores 404 y enlaces rotos
Si gran parte de tu web devuelve errores, Google desperdicia su presupuesto de rastreo y puede dejar páginas válidas sin visitar. - Cadenas de redirecciones largas o bucles
Cada salto adicional ralentiza el rastreo y puede hacer que Google abandone antes de llegar al destino final. - Bloquear accidentalmente recursos esenciales
Si Google no puede cargar CSS o JavaScript, no entiende bien el diseño ni el contenido de la página.
Errores que bloquean la indexación
- Etiquetas noindex aplicadas por error
Muy común en webs que salen de un entorno de desarrollo sin limpiar estas directrices. - Canonical mal configurado
Si una página apunta como canónica a otra URL, Google puede ignorarla y dejarla fuera del índice. - Contenido duplicado o near-duplicate
Versiones con y sin www, http/https, mayúsculas/minúsculas o parámetros pueden generar duplicidad. - Thin content (contenido pobre o escaso)
Páginas con muy poco texto, sin valor añadido o generadas automáticamente suelen ser descartadas. - Bloqueos en meta robots o cabeceras HTTP
Un simplenoindexox-robots-tagmal aplicado puede desindexar secciones completas. - Problemas de renderizado con JavaScript
Si el contenido principal depende de JS y Google no lo interpreta correctamente, la página puede quedar vacía a sus ojos. - Velocidad de carga muy baja
Google tiende a dejar fuera páginas extremadamente lentas o que fallan al cargarse. - Falta de compatibilidad móvil (Mobile-First Index)
Si la versión móvil no carga bien, no es usable o bloquea contenido, la indexación se ve afectada.
Errores que limitan el ranking
- Escribir solo para Google y no para el usuario
Textos sobreoptimizados, llenos de keywords, sin responder a la intención de búsqueda real. - Arquitectura de enlaces internos deficiente
Páginas importantes enterradas a demasiados clics o sin enlaces internos relevantes. - No trabajar la autoridad y popularidad de la página
Una página sin enlaces internos ni externos carece de señales de importancia frente a la competencia. - Experiencia de usuario deficiente (UX)
Páginas con intersticiales, exceso de anuncios o mala navegabilidad pueden ser penalizadas de forma indirecta. - Problemas de seguridad (HTTPS)
Páginas sin certificado SSL son vistas como poco seguras y pierden visibilidad en el ranking. - Contenido desactualizado
Google favorece contenido fresco y actualizado, especialmente en búsquedas sensibles al tiempo (ej. noticias, guías de marketing, comparativas de productos). - Mala optimización de imágenes y multimedia
Archivos pesados sin compresión ni atributos alt ralentizan la carga y dificultan la accesibilidad. - Problemas de internacionalización (hreflang)
Etiquetas mal implementadas pueden confundir a Google y mostrar la versión incorrecta en cada país/idioma.
Todos estos errores son fáciles de evitar con una buena auditoría SEO inicial y una estrategia clara.
Cómo aplicar este proceso a tu propia web
Vamos a aterrizarlo con un caso práctico. Supón que tienes una tienda online de muebles y acabas de lanzar una nueva categoría: “Mesas de comedor de diseño”.
- Rastreo: te aseguras de enlazar esta categoría desde el menú principal y que aparezca en el sitemap.
- Indexación: redactas una descripción única, con títulos bien optimizados y fotografías con atributos alt.
- Ranking: trabajas el enlazado interno desde artículos de blog como “Tendencias en decoración de salones” y buscas colaboraciones para conseguir backlinks de revistas de diseño.
Con estos pasos, no solo garantizas que Google encuentre la página, sino que además la valore lo suficiente para empezar a escalar posiciones.
Herramientas esenciales para rastreo, indexación y ranking
En EximiaStudio usamos una combinación de herramientas que nos permiten tener control total sobre el proceso. Aquí te dejo las imprescindibles:
- Google Search Console: gratuita y básica para entender rastreo e indexación.
- Screaming Frog: para analizar la arquitectura y detectar errores técnicos.
- Ahrefs o SEMrush: potentes para estudiar backlinks, autoridad y ranking.
- Google Analytics 4: mide el comportamiento real de los usuarios en tu web.
- PageSpeed Insights: evalúa velocidad y Core Web Vitals.
- Extensiones de Chrome:
- SEO Minion: para analizar títulos, meta descripciones y enlaces en una página.
- Check My Links: ideal para revisar enlaces rotos en segundos.
- Keywords Everywhere: muestra volúmenes de búsqueda directamente en Google.
Cada una tiene su función, y juntas crean un ecosistema perfecto para monitorizar la salud SEO de cualquier proyecto.
Por qué contratar a un profesional en SEO
Sí, puedes intentar hacerlo tú mismo. Pero la realidad es que el SEO es como un iceberg: lo que ves en la superficie (palabras clave, títulos, descripciones) es solo una pequeña parte. Debajo hay cientos de factores técnicos, estratégicos y de negocio que marcan la diferencia entre aparecer en la página 10 o dominar el top 3.
En EximiaStudio trabajamos precisamente ahí: unimos estrategia de negocio, conocimiento técnico y creatividad para que el SEO no sea solo “salir en Google”, sino convertir búsquedas en ventas reales. Y es que, al final, de nada sirve tener visibilidad si no logras transformar ese tráfico en clientes. Si quieres dar un paso más y descubrir cómo hacerlo, te recomiendo nuestra guía sobre cómo atraer clientes a tu página web con estrategias para convertir visitas en ventas, donde explicamos técnicas prácticas que puedes aplicar desde hoy mismo para que tu web se convierta en un verdadero canal de captación.
Además, un profesional te ayuda a:
- Priorizar qué optimizaciones tienen más impacto inmediato.
- Evitar errores que pueden penalizar tu web.
- Diseñar una estrategia a medio y largo plazo que genere resultados sostenibles.
- Monitorizar y adaptar la estrategia con datos reales.
Invertir en SEO con expertos no es un gasto, es la mejor inversión a largo plazo que puedes hacer para tu negocio digital.
Conclusión
Entender cómo funciona Google —desde el rastreo hasta la indexación y el ranking— es esencial para cualquier proyecto digital. Sin rastreo, Google no descubre tu web; sin indexación, no la guarda en su base de datos; sin ranking, no tendrás visibilidad frente a tus competidores.
La clave está en facilitarle la vida a Google y al mismo tiempo ofrecer valor real al usuario. Eso significa trabajar la técnica, el contenido y la autoridad de manera conjunta. Para tener una visión más completa y actualizada, puedes revisar nuestra Guía SEO para optimizar tu negocio, donde encontrarás un plan paso a paso con estrategias adaptadas a los cambios más recientes del algoritmo.
Si quieres asegurarte de que tu proyecto no solo está en Google, sino que además aparece donde realmente importa, en EximiaStudio te podemos ayudar. Hablemos de tu estrategia SEO y veamos juntos cómo hacer que Google trabaje a tu favor.
Impulsa tu negocio por internet y consigue más clientes
¡Cuéntanos tu proyecto! Rellena el siguiente formulario





